N+1查询问题是一个长期存在的数据库性能问题。它影响了许多ORM和自定义SQL代码,Django的ORM也是
N+1 查询问题是一个长期存在的数据库性能问题。它影响了许多 ORM 和自定义 SQL 代码,Django 的 ORM 也是
Django Object-Relational Mapper(ORM) 作为 Django 比较受欢迎的特性,在开发中被大量使用。我们可以通过它和数据库进行交互,实现 DDL 和 DML 操作.
QuerySet 本质上是通过在预先定义好的 model 中的 Manager 和数据库进行交互,Manager 是 Django model 提供数据库查询的一个接口,在每个 Model 中都至少存在一个 Manager 对象。
Django 开发者必须了解的知识之一就是 QuerySet 是惰性的,但是很多时候仅仅是知道一句获取数据时才会去进行 SQL 查询,忽略了 惰性 这个特性对代码实际性能对影响,以及查询后缓存对数据可能造成的影响,这里将对这个问题进行探讨
1. 什么是 N+1 问题?
简而言之:代码循环遍历一个查询的结果列表,然后对每个结果执行另一个查询。
假设以下模型
class Book(model.Model):
"""书籍"""
models.ForeignKey(Author) # 这里忽略了其他参数
pass
class Author(model.Model):
"""作者"""
models.ForeignKey(Country)
pass
class Country(model.Model):
"""城市"""
pass
1.1 N+1 查询
如果我们有一个携带 QuerySet 的循环代码
books = Book.objects.order_by("title")
for book in books:
print(book.title, "by", book.author.name)
这里的 print 可能会被输出到序列化器中,可能会被输出到模板中,看起来没有什么问题,但是仔细分析一下
-
第一行,在我们进行查询后,由于 QuerySet 惰性,并没有执行实际的 SQL
-
第二行,我们需要循环上面获取到的结果,这里需要进行 1 次实际的 SQL 查询
SELECT id, title, author_id, ... FROM book ORDER BY title -
第三行,我们对循环结果引入到实际的业务中,这里由于
author是一个关联外建,每次 Django 都会查询当前循环对象所关联的author,数量为 n,n 为第二行查询获得的 books 数量-- id为上面查询的author_id SELECT id, name, ... FROM author WHERE id = %s
这样累计下来,这里一共执行了 n+1 次查询,每一次数据库查询的性能消耗都是不可忽视的,涉及 SQL 服务通信,数据库 IO,CPU 性能等各方面影响,如果 n 累计下来,这里就会产生严重的性能问题
1.2 2N+1 查询
上面的例子中,如果我们再获取作者的城市信息
books = Book.objects.order_by("title")
for book in books:
print(
book.title,
"by",
book.author.name,
"from",
book.author.country.name,
)
此时,循环第三步每次循环将增加对 country 表的查询,所以现在的总查询次数是 2n+1
1.3 NM+N+1 查询
在实际的业务中,一本书将拥有多个作者,所以此时,ORM 语句将变成这样
books = Book.objects.order_by("title")
for book in books:
print(book.title, "by: ", end="")
names = []
for author in book.authors.all():
names.append(f"{author.name} from {author.country.name}")
print(", ".join(names))
首先获得 n 本书,每本书获取 m 次作者信息及 n 次城市信息,而我们实际的业务逻辑只会更加复杂,这种情况不加以限制将会严重拖慢系统性能,而我们要做的就是每一次实际的查询中,尽量获取到后面要用的数据,降低 SQL 查询成本
2. 如何解决 N+1 问题
django 给我们提供了两个将多次查询集成为一个复杂查询的方法,select_related 和 prefetch_related
它们的工作方式相似——都在原始查询的同时获取相关的模型。不同之处在于,select_related() 在同一个查询中获取相关的实例,而 prefetch_related() 使用第二个查询。
2.1 select_related
返回一个
QuerySet,它将“跟随”外键关系,在执行查询时选择额外的相关对象数据。这是一个性能提升器,它导致一个更复杂的单一查询,但意味着以后使用外键关系将不需要数据库查询。
books = Book.objects.order_by("title").select_related("author")
for book in books:
print(book.title, "by", book.author.name)
由于使用了 select_related 预加载作者信息,循环体中,不会再去数据库中查询作者
同时,针对 2n+1 的问题,select_related 支持声明链式关系
Book.objects.order_by("title").select_related("author", "author__country")
select_related 合并后的 SQL 类似于
SELECT
book.id,
book.title,
book.author_id,
...,
author.id,
author.name,
...
FROM
book
INNER JOIN author ON (book.author_id = author.id)
ORDER BY book.title
从原始 SQL 中可以看出,select_related 存在可能获取重复数据的问题,例如
| book.id | book.title | book.author_id | author.id | author.name |
|---|---|---|---|---|
| 123 | The Hundred and One Dalmatians | 678 | 678 | Dodie Smith |
| 234 | The Hound of the Baskervilles | 789 | 789 | Arthur Conan Doyle |
| 345 | The Lost World | 789 | 789 | Arthur Conan Doyle |
- 如果重复的部分涉及一些较大的字段,总查询集将会很大
select_related为了避免因跨越“many”关系进行连接而产生更大的结果集,select_related仅限于单值关系 —— 外键和一对一
为了更好的支持一对多或者多对多的关系和避免多表 join 后产生的巨大结果集以及效率问题,我们需要用到 prefetch_related
2.2 prefetch_related
返回一个
QuerySet,它将在一个批次中自动检索每个指定查询的相关对象
select_related 的工作方式是创建一个 SQL 连接,并在 SELECT 语句中包含相关对象的字段。
prefetch_related 则对每个关系进行单独的查找,并在 Python 中进行“joining”。这使得它除了支持 select_related 的外键和一对一关系外,还可以预取多对多和多对一的对象,这是用 select_related 无法做到的。它还支持 GenericRelation 和 GenericForeignKey 的预取,但是,它必须限制在一组同质的结果中。例如,只有当查询仅限于一个 ContentType 时,才支持预取 GenericForeignKey 引用的对象。
2.2.1 还是上面的例子
prefetch_related 与 select_related 的使用方式很相似
books = Book.objects.order_by("title").prefetch_related("author")
for book in books:
print(book.title, "by", book.author.name)
区别在于第三行第二次进行 SQL 查询时才获取作者信息,查看原始 SQL 更方便理解一点
第一次查询原始 SQL
SELECT
id,
title,
author_id,
...
FROM book
ORDER BY title
第二次查询原始 SQL
SELECT
id,
name,
...
FROM author
WHERE id IN (%s, %s, ...)
使用 prefetch_related 进行链式声明也与 select_related 相同,但是这里有三次查询,一个查询图书,一个查询作者,一个查询作者所在国家
Book.objects.order_by("title").prefetch_related("author", "author__country")
同时,面对多对多的情况,即 NM + N + 1 的情况,prefetch_related 也能够支持,同样是三次查询(注意 author 带了 s)
Book.objects.order_by("title").prefetch_related("authors", "authors__country")
2.2.2 再换个例子
假设这样一个模型
from django.db import models
class Topping(models.Model):
name = models.CharField(max_length=30)
class Pizza(models.Model):
name = models.CharField(max_length=50)
toppings = models.ManyToManyField(Topping)
def __str__(self):
return "%s (%s)" % (
self.name,
", ".join(topping.name for topping in self.toppings.all()),
)
如果运行
>>> Pizza.objects.all()
["Hawaiian (ham, pineapple)", "Seafood (prawns, smoked salmon)"...
这样做的问题是,输出到控制台时,回调用 __str__ 方法,而我们重载的方法中调用 self.toppings.all() ,每一条数据都会进行一次查询
使用 prefetch_related 可以把查询减少到两次
>>> Pizza.objects.all().prefetch_related('toppings')
["Hawaiian (ham, pineapple)", "Seafood (prawns, smoked salmon)"...
这里每次调用 self.toppings.all() 时,将会从 QuerySet 缓存中获取,不会再去执行数据库链接
注意 ⚠️:这里在
.all()的前提下使用的prefetch_related,如果将上面ORM语句获取的QuerySet结果赋值给变量后,不能再用如filter,order_by等ORM语句去操作,否则仍然会去进行数据库查询,当然如果仍要使用,也可以附加prefetch_related操作
请注意,主 QuerySet 的结果缓存和所有指定的相关对象将被完全加载到内存中。这改变了 QuerySets 的典型行为,它通常试图避免在需要之前将所有对象加载到内存中,即使在数据库中执行了一个查询之后。
注意 ⚠️:请记住,与
QuerySets一样,任何后续的链式方法,如果意味着不同的数据库查询,将忽略之前缓存的结果,并使用新的数据库查询来检索数据。所以,如果你写了以下内容:>>> pizzas = Pizza.objects.prefetch_related('toppings') >>> [list(pizza.toppings.filter(spicy=True)) for pizza in pizzas]那么
pizza.toppings.all()已经被预取的事实对你没有帮助。prefetch_related('toppings')意味着pizza.toppings.all(),但pizza.toppings.filter()是一个新的、不同的查询。预设缓存在这里帮不上忙,事实上它损害了性能,因为你做了一个你没有使用过的数据库查询。所以要谨慎使用这个功能!另外,如果你调用了
add()、remove()、clear()或set(),在related managers上,关系的任何预取缓存将被清除。
2.2.3 prefetch_related_objects
如果我们在第一次没有预取,也可以使用 prefetch_related_objects() 方法进行预取相关属性
from django.db.models import prefetch_related_objects
prefetch_related_objects(books, "author", "author__city")
2.2.4 混合使用
prefetch_related 和 select_related 允许混用,但是多对多关系中不能在 prefetch_related 后面调用 select_related,比如在官方例子中
# 这将为每家餐厅获取最好的比萨饼和最好的比萨饼的所有配料。这将在 3 个数据库查询中完成——一个查询餐厅,一个查询“最佳披萨”,一个查询配料。
# best_pizza 关系也可以用 select_related 来获取,将查询次数减少到 2:
>>> Restaurant.objects.select_related('best_pizza').prefetch_related('best_pizza__toppings')
由于预取是在主查询之后执行的(其中包括 select_related 所需要的连接),它能够检测到 best_pizza 对象已经被取走了,它将跳过再次取走它们。
链式调用 prefetch_related 将累积预取的查找。要清除任何 prefetch_related 行为,传递 None 作为参数:
>>> non_prefetched = qs.prefetch_related(None)
虽然
prefetch_related支持预取GenericForeignKey关系,但查询次数将取决于数据。由于一个GenericForeignKey可以引用多个表中的数据,所以需要对每个被引用的表进行一次查询,而不是对所有项目进行一次查询。如果还没有获取相关的行,可以对ContentType表进行额外的查询。
2.2.5 数据库本身的问题
2.2.1 中我们写的原始 SQL,prefetch_related 将 ORM 语句翻译成带有 IN 的语句,在不同数据库中可能出现不同性能问题,假如 IN 字段是一个带索引的字段,mysql 5.6 以前的版本将不会走索引,这一点需要特别注意一下
2.2.6 使用 Prefetch 对象进一步控制
class Prefetch(lookup, queryset=None, to_attr=None):
pass
Prefetch() 对象可以用来控制 prefetch_related() 的操作
lookup 参数描述了要遵循的关系,并且与传递给 prefetch_related() 的基于字符串的查找相同。 例如
>>> from django.db.models import Prefetch
>>> Question.objects.prefetch_related(Prefetch('choice_set')).get().choice_set.all()
<QuerySet [<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]>
# This will only execute two queries regardless of the number of Question
# and Choice objects.
>>> Question.objects.prefetch_related(Prefetch('choice_set')).all()
<QuerySet [<Question: What's up?>]>
queryset 参数为给定的查询提供基本的 QuerySet。 这对于进一步过滤预取操作或从预取关系中调用 select_related() 很有用,从而进一步减少了查询数量:
>>> voted_choices = Choice.objects.filter(votes__gt=0)
>>> voted_choices
<QuerySet [<Choice: The sky>]>
>>> prefetch = Prefetch('choice_set', queryset=voted_choices)
>>> Question.objects.prefetch_related(prefetch).get().choice_set.all()
<QuerySet [<Choice: The sky>]>
to_attr 参数将预取操作的结果设置为自定义属性:
>>> prefetch = Prefetch('choice_set', queryset=voted_choices, to_attr='voted_choices')
>>> Question.objects.prefetch_related(prefetch).get().voted_choices
[<Choice: The sky>]
>>> Question.objects.prefetch_related(prefetch).get().choice_set.all()
<QuerySet [<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]>
当使用
to_attr时,预取结果存储在列表中。 与传统的prefetch_related调用相比,这可以显着提高速度,传统的prefetch_related调用将缓存的结果存储在QuerySet实例中。
最简单的形式 Prefetch 相当于传统的基于字符串的查找。
>>> from django.db.models import Prefetch
>>> Restaurant.objects.prefetch_related(Prefetch('pizzas__toppings'))
你可以用可选的 queryset 参数提供一个自定义查询集。这可以用来改变查询集的默认排序。
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas__toppings', queryset=Toppings.objects.order_by('name')))
或者在适用的时候调用 select_related(),以进一步减少查询次数。
>>> Pizza.objects.prefetch_related(
... Prefetch('restaurants', queryset=Restaurant.objects.select_related('best_pizza'))
... )
你也可以用可选的 to_attr 参数将预取结果分配给一个自定义属性。结果将直接存储在一个列表中。
这允许用不同的 QuerySet 预取同一关系多次;例如:
>>> vegetarian_pizzas = Pizza.objects.filter(vegetarian=True)
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas', to_attr='menu'),
... Prefetch('pizzas', queryset=vegetarian_pizzas, to_attr='vegetarian_menu')
... )
使用自定义 to_attr 创建的查找仍然可以像往常一样被其他查找遍历。
>>> vegetarian_pizzas = Pizza.objects.filter(vegetarian=True)
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas', queryset=vegetarian_pizzas, to_attr='vegetarian_menu'),
... 'vegetarian_menu__toppings'
... )
在对预取结果进行过滤时,建议使用 to_attr,因为它比将过滤后的结果存储在相关管理器的缓存中更不含糊。
>>> queryset = Pizza.objects.filter(vegetarian=True)
>>>
>>> # Recommended:
>>> restaurants = Restaurant.objects.prefetch_related(
... Prefetch('pizzas', queryset=queryset, to_attr='vegetarian_pizzas'))
>>> vegetarian_pizzas = restaurants[0].vegetarian_pizzas
>>>
>>> # Not recommended:
>>> restaurants = Restaurant.objects.prefetch_related(
... Prefetch('pizzas', queryset=queryset))
>>> vegetarian_pizzas = restaurants[0].pizzas.all()
自定义预取也适用于单一的相关关系,如前向 ForeignKey 或 OneToOneField。一般来说,你会希望使用 select_related() 来处理这些关系,但在一些情况下,使用自定义 QuerySet 进行预取是有用的。
-
你要使用一个
QuerySet,对相关模型进行进一步的预取。 -
你想只预取相关对象的一个子集。
-
你要使用性能优化技术,比如
递延字段>>> queryset = Pizza.objects.only('name') >>> >>> restaurants = Restaurant.objects.prefetch_related( ... Prefetch('best_pizza', queryset=queryset))
当使用多个数据库时,Prefetch 将尊重你对数据库的选择。如果内部查询没有指定数据库,它将使用外部查询选择的数据库。以下所有情况都是有效的:
>>> # Both inner and outer queries will use the 'replica' database
>>> Restaurant.objects.prefetch_related('pizzas__toppings').using('replica')
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas__toppings'),
... ).using('replica')
>>>
>>> # Inner will use the 'replica' database; outer will use 'default' database
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas__toppings', queryset=Toppings.objects.using('replica')),
... )
>>>
>>> # Inner will use 'replica' database; outer will use 'cold-storage' database
>>> Restaurant.objects.prefetch_related(
... Prefetch('pizzas__toppings', queryset=Toppings.objects.using('replica')),
... ).using('cold-storage')
查询的顺序很重要,举例子
>>> prefetch_related('pizzas__toppings', 'pizzas')
即使它是无序的,这也是可行的,因为 pizzas__toppings 已经包含了所有需要的信息,因此第二个参数 pizzas 实际上是多余的
>>> prefetch_related('pizzas__toppings', Prefetch('pizzas', queryset=Pizza.objects.all()))
这将引发一个 ValueError,因为它试图重新定义一个先前看到的查询的查询集。请注意,一个隐式查询集被创建为遍历 pizzas 作为 pizzas__toppings 查询的一部分。
>>> prefetch_related('pizza_list__toppings', Prefetch('pizzas', to_attr='pizza_list'))
这将触发一个 AttributeError,因为 pizza_list 在处理 pizza_list__toppings 时还不存在
这种考虑不限于使用 Prefetch 对象。一些高级技术可能要求按照特定的顺序进行查找,以避免产生额外的查询;因此,建议总是仔细地安排 prefetch_related 参数的顺序。
2.2.7 不要与 iterator 一起用
iterator 常用于迭代 QuerySet 优化,但是不要和 prefetch_related 一起用,django 会忽略 prefetch_related,没有意义
实际开发过程中我们需要合理使用 select_related 和 prefetch_related,前者主要类似于 join,后者主要类似 in,两者绝大多数情况下通用,但一定比原始的 N 次查询方案要高效
3. 排查工具
3.1 Django-debug-toolbar
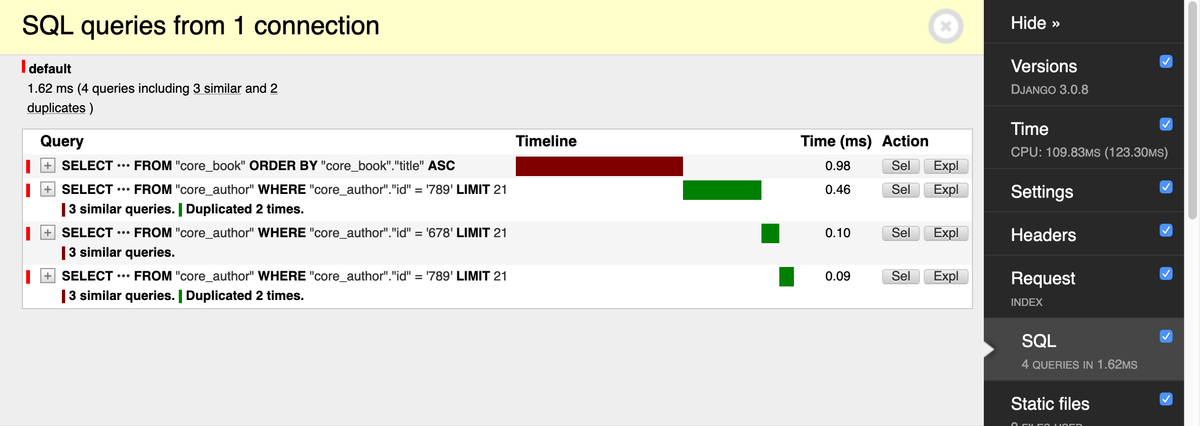
面板用文本突出显示了 N 个查询: Author
3 类似查询。重复 2 次。
我们可以展开查询以查看其完整的 SQL 和堆栈跟踪。这使我们能够在代码中发现有问题的行,但是不能作用于生产
3.2 nplusone
会检测潜在的 N+1 警告,但是近两年没有更新
3.3 Scout ARM
收费的 python 项目探针
3.4 py-spy
可以试试观察项目进程及子进程的 CPU,GIL 占用情况,同时可以收集任意时间的运行数据,生成火焰图,便于排查问题
# 实时
sudo py-spy top --pid 17010 --idle --gil --subprocesses
# 火焰图
sudo py-spy record --pid 17010 --idle --gil --subprocesses



